
You can send or ingest all sorts of data in ElasticSearch and here and there you might have the need to enrich or transform certain data. ElasticSearch has some nice features for this. They are called ‘Ingest Nodes’:
Ingest Nodes are a new type of Elasticsearch node you can use to perform common data transformation and enrichments.
The Ingest Node has multiple built-in processors, for example grok, date, gsub, lowercase/uppercase, remove and rename. You can find a full list in the documentation.
Besides those, there are currently also three Ingest plugins:
- Ingest Attachment converts binary documents like Powerpoints, Excel Spreadsheets, and PDF documents to text and metadata
- Ingest Geoip looks up the geographic locations of IP addresses in an internal database
- Ingest user agent parses and extracts information from the user agent strings used by browsers and other applications when using HTTP
Requirements
I just wanted a simple processor which always uppercased a certain field. So basically I had to setup a pipeline with an uppercase processor. The thing is, I do wanted to test it first. They also thought about that! You can use the simulate API to test your pipeline. See https://www.elastic.co/guide/en/elasticsearch/reference/master/simulate-pipeline-api.html.
So let’s see how that looks like:
POST _ingest/pipeline/_simulate
{
"pipeline" :
{
"description": "_description",
"processors": [
{
"uppercase": {
"field": "merkCode"
}
}
]
},
"docs": [
{
"_index": "index",
"_type": "_doc",
"_id": "id",
"_source": {
"merkCode": "vgz"
}
}
]
}
First we create pipeline and give it a description. When PUTing your actual pipeline, use a decent name. Next define the processor. Mine is just uppercasing the field merkCode. At the end, you can define test data to simulate your pipeline. Just input this in your devtools window and run it.
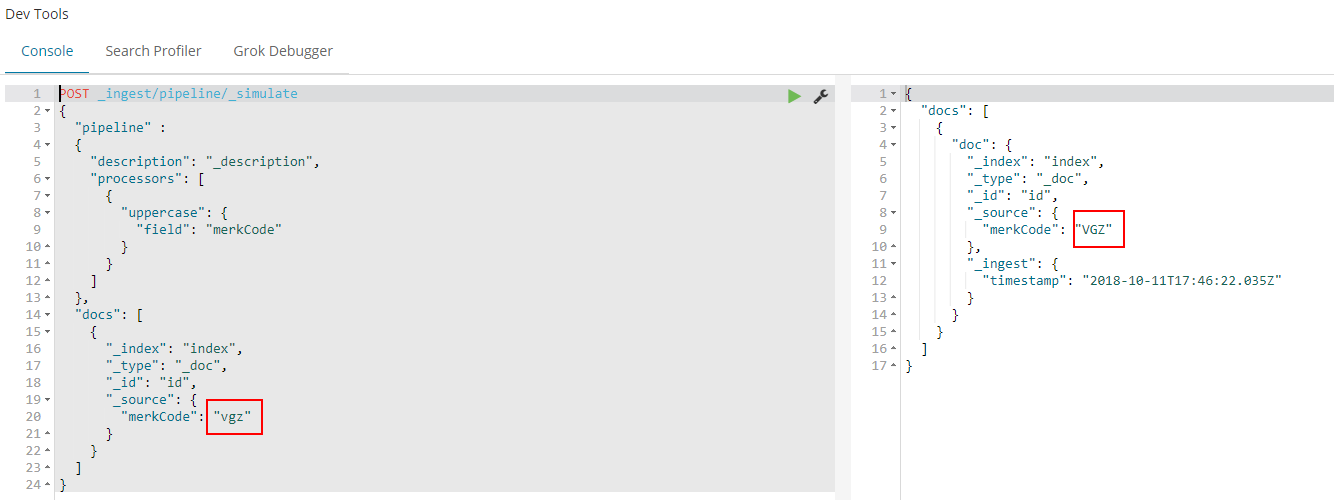
Now that we have seen that it works, it is time to PUT it to work.
PUT _ingest/pipeline/uppercase_merkCode
{
"processors": [
{
"uppercase": {
"field": "merkCode"
}
}
]
}
Result:
{
"acknowledged": true
}
To make use of the pipeline you have to add it to the PUT action like this:
PUT my_index/_doc/my-id?pipeline=uppercase_merkcode
{
"service": "MyService",
"operatie": "MyOperation",
"datum": "2018-10-11T22:37:34.205+02:00",
"merkCode": "vgz",
}
As you can see, this is a very powerfull way to easily enrich or transform data.